
ChatGPT in den Geschichtswissenschaften? Ein Praxisversuch
ChatGPT in den Geschichtswissenschaften? Ein Praxisversuch
07.03.23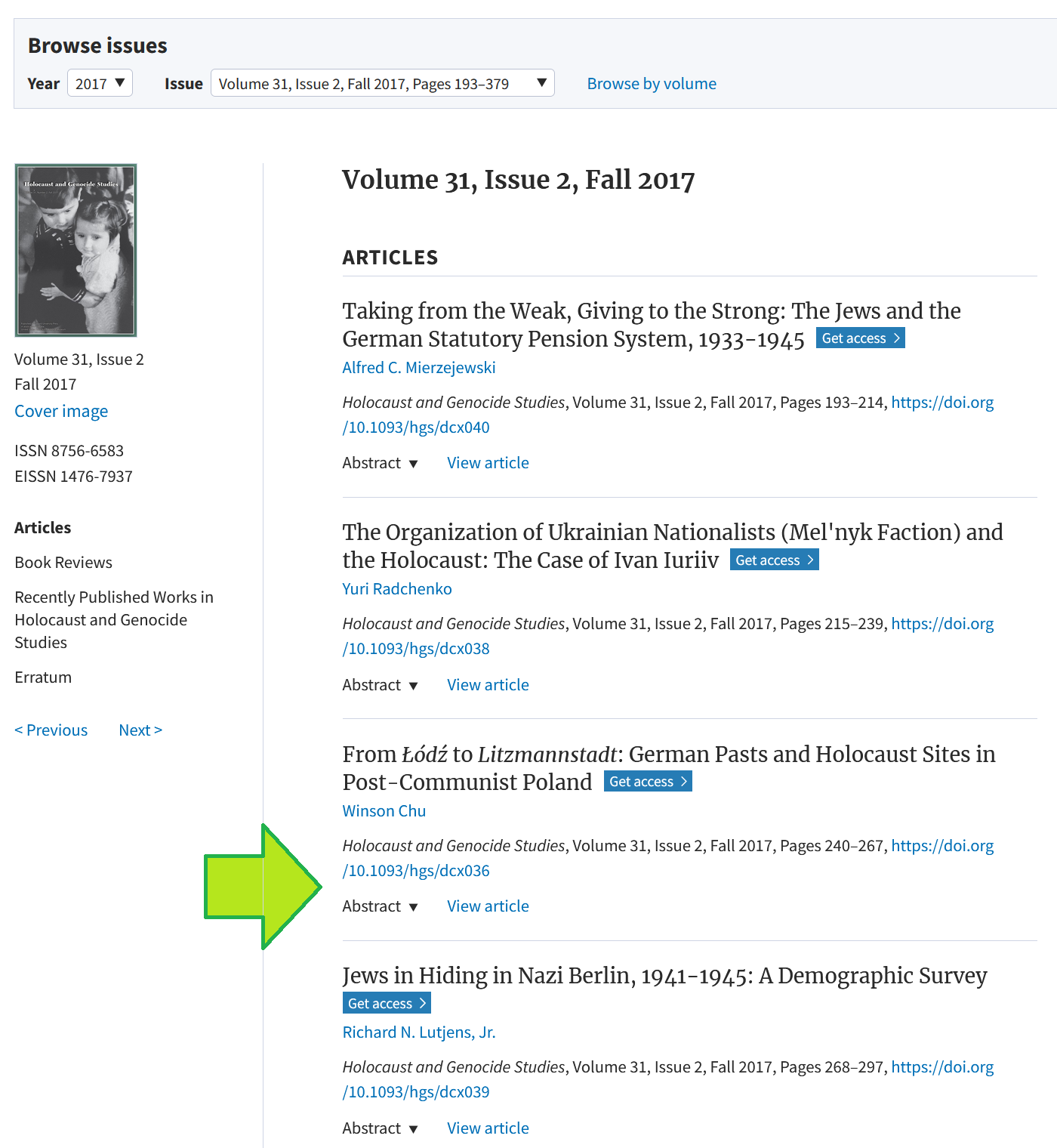

ChatGPT kann gut lesbare Texte generieren, die aber noch nicht wissenschaftlichen Standards genügen. Doch worauf können und sollten Lehrende konkret im Umgang mit automatisch generierten Texten achten? Wo liegen mögliche Fehlerquellen? Sophie Eckenstaler, Wissenschaftliche Mitarbeiterin an der Professur für „Digital History“ an der Humboldt-Universität zu Berlin, erkundet anhand eines Praxisbeispiels aus den Geschichtswissenschaften die Reichweiten und Grenzen.

Das Beispiel Topf & Söhne
Im Kontext von ChatGPT an Hochschulen wurde in den vergangenen Wochen vielfach diskutiert, ob durch den Textgenerator das Ende der klassischen wissenschaftlichen Hausarbeit als Prüfungsformat insbesondere in den geisteswissenschaftlichen Fächern eingeläutet wurde.
Im Kern stellt sich hier die Frage, ob ChatGPT fähig ist, wissenschaftlich zu schreiben. Um diese zu beantworten, wurde der Textgenerator an einem exemplarischen geschichtswissenschaftlichen Beispiel getestet (vgl. 1). Dazu wurde folgende Aufgabenstellung (im Original auf Englisch) im ChatGPT-Prompt eingegeben:
Verfasse einen zusammenfassenden (vgl. 2) wissenschaftlichen Text zur Rolle der Firma Topf & Söhne im Vernichtungslager Auschwitz unter Angabe von Literatur und Quellen (vgl. 3).
](/sites/default/files/images/blog/ChatGPT-answer-Topf_Sons.png "Abbildung 1 zeigt die Antwort, die ChatGPT nach kurzer Zeit lieferte. [Textprompt von ChatGPT, Quelle: https://chat.openai.com/ (Zugriff am 15.01.2023)](ChatGPT-answer-Topf_Sons.png)]")
Erster Eindruck: Formal korrekt, sprachlich überzeugend, thematisch zutreffend
Der erste Eindruck ist zunächst, dass der Text formal korrekt ist. Es gibt eine Einleitung mit Hinführung zum Thema, einen Hauptteil mit Fokus auf den Forschungsstand sowie eine abschließende Einschätzung. Auch Literatur und Quellen werden direkt im Text nachgewiesen sowie am Ende aufgelistet.
Ins Auge fällt vor allem die Sprachgewandtheit des Chatbots, die – zumindest in diesem Beispiel – nicht mehr eindeutig erkennen lässt, ob der Text von einem Mensch geschrieben oder von einer Maschine generiert wurde.
Darüber hinaus wird inhaltlich die wesentliche Information zum Thema genannt, nämlich dass die deutsche Firma Topf & Söhne die Krematorien in Auschwitz baute sowie Leichenverbrennungsöfen dorthin lieferte.
Gründlicher Blick: Forschungsstand überholt…
Im Detail zeigt sich jedoch, dass der Text inhaltlich weit hinter den aktuellen Forschungsstand zurückfällt. Dies wird im Folgenden an drei Textauszügen illustriert:
…as a supplier of crematoria and incineration equipment to the Auschwitz concentration camp…
Diese Antwort ist nicht falsch, unterschlägt aber im Fall von Auschwitz eine wichtige Information hinsichtlich der Bewertung der Rolle von Topf & Söhne. Denn die Firma stellte hier nicht nur die Verbrennungstechnik zur Beseitigung der Leichen bereit, sondern auch die Lüftungstechnik für die im Kellergeschoss der Krematorien II und III liegenden Gaskammern. Das Ziel war, den Luftaustausch zu beschleunigen und dadurch den Massenmord schneller fortsetzen zu können. Folglich war Topf & Söhne auch an der Optimierung der Tötung von Menschen beteiligt (vgl. 4).
…profited economically from the systematic extermination of Holocaust victims.
Es liegt bei dem Thema nahe, dass der Text auf rein wirtschaftliche Aspekte fokussiert. Im Fall von Topf & Söhne ist es jedoch eine verkürzte, wenn nicht sogar unzutreffende Darstellung. Der Gewinn mit den Lagerkrematorien machte nicht einmal 2% des Gesamtumsatzes aus und hatte insgesamt also keine existentielle Bedeutung für die Firma. Auch naheliegende Motive wie Zwang oder Antisemitismus gelten nicht. Tatsächlich waren sie viel banaler und alltäglicher. So waren Motive wie technologische Herausforderungen, Status und berufliche Anerkennung, Konkurrenz unter den Ingenieuren sowie persönliche Vorteile vor allem handlungsentscheidend bei der Zusammenarbeit mit der SS (vgl. 5). Kurz gesagt, ist die Folgerung im Text plausibel und doch faktisch falsch.
Further research is needed to fully understand the implications of Topf & Sons actions during the Holocaust.
Ferner wird im Text behauptet, dass weitere Forschung notwendig sei. Das Gegenteil ist jedoch bei Topf & Söhne der Fall, denn die Firmengeschichte ist inzwischen sehr gut aufgearbeitet. Sicher gibt es bezüglich der Mittäterschaft privatwirtschaftlicher Unternehmen im Nationalsozialismus auch heute noch konkreten Forschungsbedarf, aber Topf & Söhne gehört nicht dazu. Auffällig ist, dass die eigentliche wissenschaftlich-historische Forschung im Text vollkommen unerwähnt bleibt (vgl. 6).
…veraltete und fragliche Literatur
Weist die auszugshafte Untersuchung oben bereits darauf hin, dass der Text einer wissenschaftlichen Qualitätsprüfung nicht standhält, offenbart dies der Blick auf die verwendete Literatur umso deutlicher: , 2017.]")
- Es wurde durchgehend keine wissenschaftliche Literatur herangezogen. Zudem ist die verwendete Literatur teilweise veraltet.
- Die ausgewählte Literatur besitzt keine Relevanz für das Thema. Der zitierte Jules Schelvis war Überlebender des Vernichtungslagers Sobibor, der seine Erinnerungen später publizierte. Allerdings gab es in Sobibor keine Krematorien und Topf & Söhne war für die SS an diesem Ort nie tätig. Noch extremer ist es bei Finkelstein, der zwar in seiner Veröffentlichung eine Holocaust-Industrie thematisierte, damit aber die umstrittende These einer „Holocaust-Industrie“ auf jüdischer Seite in den USA nach 1945 aufstellte. In beiden Fällen zeigt sich abschließend, dass der Bezug zur Firma Topf & Söhne gänzlich fehlt.
- Die unten in der Liste zuletzt genannte Literatur „Topf & Sons and the Holocaust“ (2017) ist geradewegs entlarvend für den Text, da sie überhaupt nicht existiert. Dies lässt sich sehr einfach anhand der Open Access-Ausgabe des Journals Holocaust and Genocide Studies überprüfen (vgl. 7). An der eigentlich zu erwartenden Stelle des Artikels, findet sich ein anderer, noch dazu mit einem anderen Themenschwerpunkt (grüner Pfeil in Abbildung 2). Es ist festzuhalten, dass es die Zeitschrift und auch eine in dieser mit zwei Artikeln vertretenen Autorin Melissa Jane Taylor (vgl. 8) zwar gibt, die Angabe in der Kombination wie im Text aber eine (kreative) Erfindung des Chatbots bleibt.
- Die einzigen relevanten und existenten Literaturangaben im Text sind die Publikationen des französischen Apothekers Jean-Claude Pressac (1989 und 1993). Davon abgesehen, dass es sich hierbei um die am längsten zurückliegende Forschung zum Thema handelt, ist die Verwendung zumindest im Text insofern problematisch, als dass der Autor selbst nicht weiter kontextualisiert wird. Denn dieser war mit seiner Forschung in den 70er Jahren ursprünglich mit dem Ziel angetreten, den Beweis für die Nichtexistenz der Gaskammern zu liefern (vgl. 9). Zwar gehört auch zur Wahrheit, dass Pressac sich im Laufe seiner Forschung von holocaustleugnerischen Ansichten distanzierte sowie wichtige Quellen erstmals auswertete und sicherte. Aber gerade von einem wissenschatftlichen Text sollte diese Kontextualisierungsleistung zwingend erbracht werden.
Fazit: Was der Praxisversuch zeigt
An dem geschichtswissenschaftlichen Beispiel Topf & Söhne ist anschaulich die Funktionsweise von Large Language Models (LLMs) zu erkennen und wo die Grenzen des Systems (noch) liegen. Die wichtigsten Punkte sind zusammengefasst:
- ChatGPT ist ein Textgenerator, der auf Token-Ebene (Wörter, Sätze…) Texte nach Berechnungen (word embedding, Wahrscheinlichkeitsverteilung etc.) erstellt und damit Sprache imitiert. Deren Inhalte können statistisch gesehen plausibel und gleichzeitig (trotzdem) falsch sein. Oder anders ausgedrückt: Unplausible Daten können wahr sein, auch wenn es unwahrscheinlich ist oder gar unmöglich scheint. Es zeigt sich hierin ein Spannungsverhältnis von Berechenbarkeit und Unberechenbarkeit, das letztlich die Komplexität unserer realen Welt widerspiegelt.
- Das Sprachmodell, auf dem ChatGPT trainiert wurde, basiert auf Daten bis zum Jahr 2021. Zum einen sind also Informationen nach 2021 dem Chatbot unbekannt. Zum anderen können vorliegende data biases zu inhaltlichen Verzerrungen führen (vgl. 10). Dies kann erklären, warum wichtige Informationen im Text zu Topf & Söhne fehlen.
- Schließlich bleiben LLMs eine Blackbox, deren Textgenese nicht einsehbar und damit Entscheidungen der KI-Algorithmen unklar bleiben. Darüber hinaus sind diese Entscheidungen nicht fix, d.h. es ist nicht sicher, dass ChatGPT beim zweiten Versuch zur Aufgabe inhaltlich exakt denselben Text liefern würde. Im Umkehrschluss bedeutet das, dass essentiell wissenschaftliche Qualitätskriterien wie Nachvollziehbarkeit und Transparenz nicht gegeben sind.
Abschließend festzuhalten ist, dass LLMs wie ChatGPT sehr gut darin sind, Texte zu generieren. Sie verstehen diese allerdings nicht, sind hier also überhaupt nicht „intelligent“. Folglich ist ChatGPT nicht fähig, Informationen selbst zu überprüfen und zu verifizieren, was aber Grundlage wissenschaftlichen Arbeitens und Voraussetzung für wissenschaftliches Schreiben ist. Diese Leistung sprengt klar die Systemgrenzen des Chatbots. Aus diesem Schluss keine Konsequenzen für Forschung und Lehre abzuleiten, wäre jedoch falsch, denn es handelt sich hierbei um eine Momentaufnahme. Es gibt bereits Ideen, LLMs mit symbolischer KI zu verknüpfen, um eine Verifizierung eben dieser generierten Inhalte automatisiert zu ermöglichen (vgl. 11).
Verweise
- Der Text basiert auf einem Vortrag, der im Rahmen der Info- und Austauschveranstaltung [Chat GPT – Fluch oder Segen generativer KIs für die universitäre Lehre?](https://makerspace.hypotheses.org/708) am 17.01.2023 an der Humboldt-Universität zu Berlin gehalten wurde.
- Aufgrund der Zeichbegrenzung von ChatGPT wurde nur eine Zusammenfassung erwartet, um sicherzugehen, dass ein den formalen Anforderungen entsprechender Text generiert wird.
- Natürlich gehört eine Literatur- und Quellenangabe zu einem wissenschaftlichen Text dazu und muss genau genommen nicht extra aufgeführt werden. Der Zusatz wurde in diesem Fall aber gemacht, um sicher zu stellen, dass ChatGPT diese erste Hürde auf jeden Fall nimmt, um sich nachfolgend auf die inhaltliche Auswertung konzentrieren zu können.
- Vgl. Schüle, Annegret: Industrie und Holocaust. Topf & Söhne – Die Ofenbauer von Auschwitz, Göttingen 2010, S. 176-184.
- Was am Beispiel Topf & Söhne besonders irritiert, gleichzeitig aber das Verhalten des großen Teils der deutschen Bevölkerung repräsentiert. Vgl. Schüle (2010), S. 370ff.
- Die Firmengeschichte wurde in den 2000er Jahren im Rahmen eines vom Bund finanzierten Forschungsprojekts an der Gedenkstätte Buchenwald wissenschaftlich intensiv aufgearbeitet und die Ergebnisse u.a. in einer internationalen Wanderausstellung publik gemacht. Seit 2011 existiert zudem der historisch-politische Erinnerungsort Topf & Söhne im ehemaligen Verwaltungsgebäude der Firma in Erfurt. Siehe Websites der beiden Einrichtungen: https://www.buchenwald.de/697/ und https://www.topfundsoehne.de/ts/de/index.html (beide letzter Zugriff am 17.02.2023)
- Siehe The United States Holocaust Memorial Museum (Hg.): Holocaust and Genocide Studies, Band 31 (Ausgabe 2), Herbst 2017, URL: https://academic.oup.com/hgs/issue/31/2 (letzter Zugriff am 18.02.2023).
- Zuletzt siehe Taylor, Melissa Jane (2016): American Consuls and the Politics of Rescue in Marseille, 1936–1941. In: ebd., Band 30 (Ausgabe 2), Herbst 2016, Seite 247–275, DOI: 10.1093/hgs/dcw043.
- Vgl. Schüle, Annegret: J. A. Topf & Söhne. Ein Erfurter Familienunternehmen und der Holocaust. Erfurt 2014, S. 97f.
- Bis dahin, dass gesellschaftliche Stereotypen und soziale Ungleichheiten reproduziert werden. Mehr zum Thema data bias siehe Lopez, Paola: Diskriminierung durch Data Bias. Künstliche Intelligenz kann soziale Ungleichheiten verstärken. In: WZB-Mitteilungen, Quartalsheft für Sozialforschung. – (2021), Heft 171, mit 5 Beiträgen als Online-Supplement: Von Computern und Menschen. die digitalisierte Gesellschaft, Seite 26-28.
- Siehe Wolfram, Stephen: Wolfram|Alpha as the Way to Bring Computational Knowledge Superpowers to ChatGPT, veröffentlicht am 09.01.2023, URL: https://writings.stephenwolfram.com/2023/01/wolframalpha-as-the-way-to-bring-computational-knowledge-superpowers-to-chatgpt/ (letzter Zugriff am 21.02.2023).
Ähnliche Beiträge
Auf dem Weg zu einer interoperablen Hochschullandschaft
Viele Hochschulangehörige träumen davon, plattformübergreifend auf umfassende Daten zugreifen und nahtlos mit anderen Lehrenden von verschiedenen Hochschulen zusammenarbeiten zu können. Studierende würden ebenfalls von einer einzelnen hochschulübergreifenden Plattform, an der sie sich anmelden können, profitieren. Und auch Hochschulmitarbeitende in der Verwaltung sehnen sich mitunter nach effizienteren Verfahren für die Anerkennung erbrachter Leistungen. Der European Digital Education Hub arbeitet derzeit an einer wichtigen Initiative, die sich genau dafür einsetzt – nämlich der Entwicklung eines europäischen Interoperabilitätsrahmens für die Hochschulbildung.
 Channa van der Brug
Channa van der Brug
